
Generative AI 101
생성형 인공지능의 개념과 기술

Generative AI가 Next Big Thing으로 급부상했다. 이미지 생성 모델로 DALL-E2 / Midjourney / Stable Diffusion(오픈 소스)이 공개되었고, 무엇보다 OpenAI의 ChatGPT가 대중에 공개되어 세간의 주목을 받았다. 또한, 구글, 메타, 마이크로소프트 같은 글로벌 빅테크 기업들도 각각 LaMDA, OPT, Godel이라는 언어 모델을 출시하며 기술 경쟁에 본격적으로 뛰어들었다.
세간의 평가를 종합했을 때, PC 통신 → 인터넷 → 모바일 순서로 이어진 ‘Big Thing’의 흐름이 생성형 인공지능으로 이어질 것으로 보인다. Gartner는 급상승 기술로 생성형 인공지능과 그 기초 모델(Foundation Model)을 꼽았고, Sequoia Capital은 ‘생성형 인공지능이 근로자의 생산성과 창의성을 적어도 10% 이상 향상할 것’이라고 했으며, NfX는 ‘생성형 기술을 Web3라고 불러야 한다’며 그 잠재력과 새로운 위상을 강조했다.
그러나 시장의 고조된 반응과 평가를 볼 때마다 기술 그 자체의 본질과 가능성을 놓치고 있다는 생각이 들어서, 생성형 인공지능의 개념과 활용, 사례, 비즈니스 기회 등을 다루는 시리즈 글을 통해 천천히 접근해보고자 한다. 첫 번째로는 지금 당장의 경쟁 양상이나 미시적인 사례보다 ‘생성형 인공지능 기본 개념’에 대해 다루고자 한다.
여러분이 Generative AI를 알아야 하는 이유
시장을 지배하는 거대한 기술은 S-Curve를 그리며 진화한다. 1980년대 맥킨지 컨설턴트 리처드 포스터가 제안한 이론으로 기술 발전 과정이 S자 곡선을 이룬다는 내용이다. 이에 따르면 결국 모든 기술은 태동기 > 비약기 > 성숙기를 거쳐 쇠퇴하지만, 어느 순간 새로운 기술이 등장한다.
새로운 기술이 도입되기 시작하면, 성숙기에 접어든 이전 기술과 새로운 기술의 도입기가 교차하는 ‘기술의 불연속 구간’이 생기는데, 여러 기술이 혼재하는 과정에서 역동성이 높아지고, 시장에는 잠재적인 성공 기회와 실패 위험이 공존하게 된다.
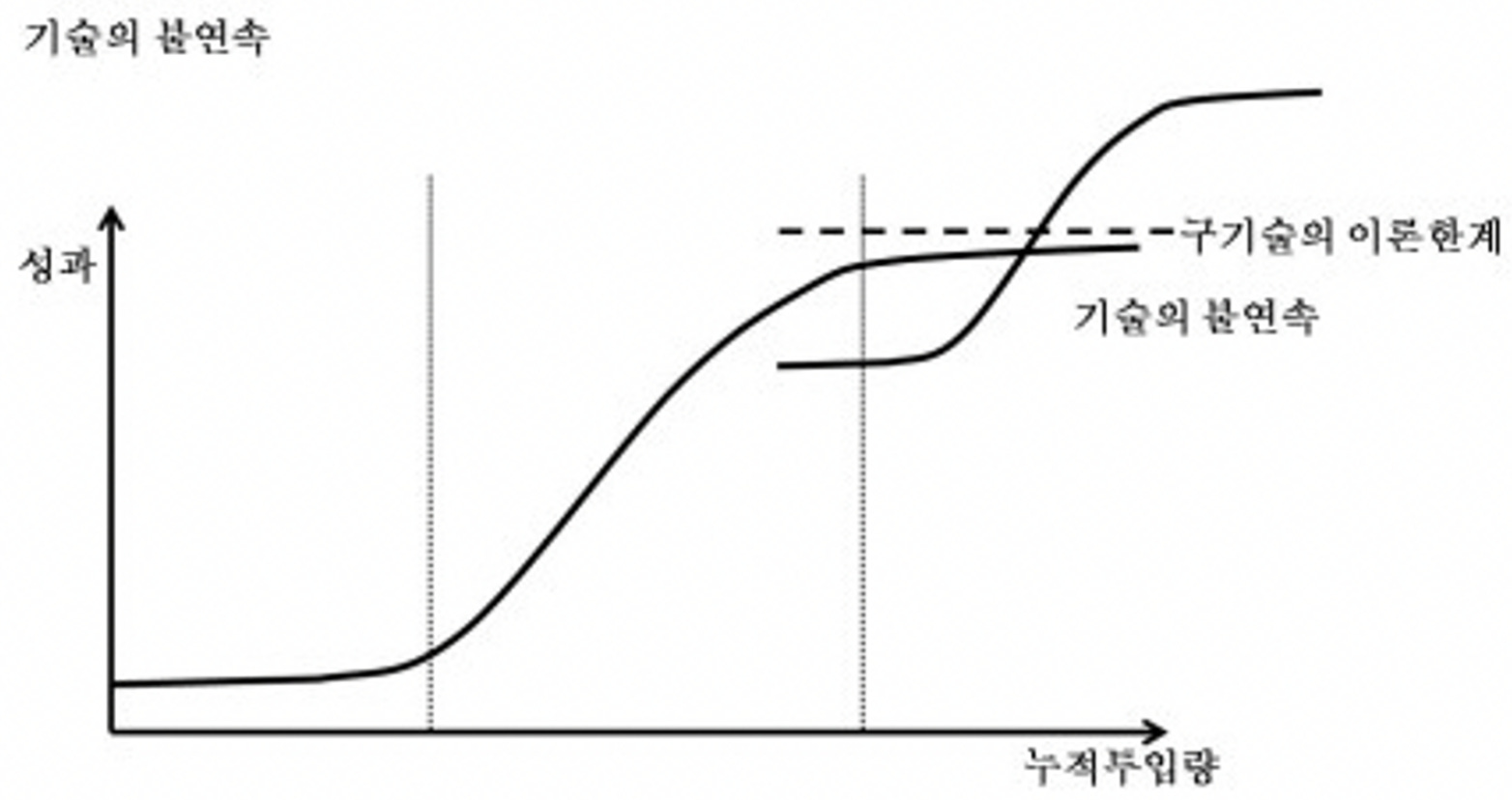
이미 인터넷과 모바일이 충분히 성숙했고 그 뒤를 이을 기술로 블록체인, VR/AR, 메타버스, 인공지능 등 다양한 기술이 나온 상황이다. 생성형 인공지능은 다른 기술과 달리 범용성이 매우 높고, API나 Application 형태로 비교적 쉽게 활용할 수 있다는 점에서 이 분야를 공부하기 시작한다면 각자의 분야에서 남들보다 빠르게 변화를 맞이하고 기회를 찾을 수 있을 것이다.
목차
Generative AI 101
①생성 모델 기반
Transformer Model
Transformer Model의 영향
Foundation Model
②기존 데이터 학습
매개 변수와 학습 데이터
학습 비용
학습 방식
③새로운 결과물 생성
적응(Adaptation)
사용(Deployment)
마무리
참고 자료
Generative AI 101
생성형 인공지능이 ‘새로운 결과물을 생성하는 기술’이라는 모호한 설명 외에 명확한 정의는 없다. 이 개념을 한 문장으로 설명하기 어려울 수 있고 그 자체가 필요 없을 수도 있겠지만, 정의는 정확한 사고의 시작점이자 논의를 진행하는 데 도움이 되므로 귀납적인 정의를 제시해보겠다.
Generative AI의 다양한 정의
Sequoia Capital : “Generative AI,” meaning the machine is generating something new rather than analyzing something that already exists.
The Digital Speaker : Generative AI is a branch of computer science that involves unsupervised and semi-supervised algorithms that enable computers to create new content / using previously created content, such as text, audio, video, images, and code.
Antler : Generative AI (Gen-AI) is a specific type of AI that is focused on generating new content, such as text, images, or music. These systems are trained on large datasets and use machine learning algorithms …
약간씩 다르게 설명하고 있지만, 이미 만들어진 자료를 활용하여 새로운 무언가를 만들어내는 머신러닝 알고리즘이라는 설명이 공통적이다. 이를 참고하여 다음과 같이 한 문장으로 정리할 수 있다.
💡 Generative AI란,
① 생성 모델을 기반으로
② 기존 데이터를 학습하여
③ 새로운 결과물을 생성하는 인공지능
①생성 모델 기반
생성 모델이란 데이터를 학습하여 학습 데이터의 분포를 따르는 유사한 데이터를 새롭게 생성하는 모델이다. AE, VAE, GAN 등 다양한 종류가 있지만, 생성형 인공지능을 이해하기 위해서는 구글이 2017년 발표한 ‘Transformer Model’를 이해해야 한다. OpenAI가 공개한 GPT의 약자가 ‘Generative Pre-trained Transformer’라는 점을 고려하면 그 중요성을 짐작할 수 있다.
Transformer Model
트랜스포머 모델이란 문장 속 단어와 같은 순차 데이터의 관계를 추적해 맥락과 의미를 학습하는 신경망이다. 입력 데이터를 덩어리로 나눠서 부분별로 중요도 가중치를 부여하는 ‘Self-attention’ 메커니즘을 활용하고, 이 메커니즘이 동시에 여러 부분에서 작용하는 ‘Multi-head attention’ 기법을 활용하여 입력 데이터를 더 잘 이해하고 정확한 결괏값을 내놓을 수 있다는 특징이 있다.
가령, ‘The cat sat on the mat’이라는 문장이 입력됐다고 가정해보자. 트랜스포머 모델은 이를 ‘The’, ‘Cat’, ‘Sat’, ‘On’, ‘The’, ‘Mat’처럼 작은 덩어리로 나누고 맥락상 중요한 단어인 ‘Cat’에는 높은 가중치를 부여하는 반면, 의미에 큰 영향이 없는 ‘The’에는 낮은 가중치를 주는 방식으로 문장을 학습하는 것이다. 이러한 방식이 사람이 문장을 읽을 때 특정 단어나 구문에 집중하는 것과 유사하여 자연어 처리(NLP)를 수행하는 대규모 언어 모델(LLM)을 구축하는 데 사용된다.
최근에는 자연어 처리 분야 뿐만 아니라 비전, 음성 등 다른 영역에서도 트랜스포머 모델을 사용하고 있다.
Transformer Model의 영향
구글의 트랜스포머 모델이 텍스트 같은 순차 데이터를 처리하는 데 적합하다는 특징이 대규모 언어 모델(LLM)의 등장에 많은 영향을 주었다. 트랜스포머 아키텍처를 따르는 대규모 언어 모델이 방대한 양의 텍스트 데이터를 학습하여 번역/요약/생성, 질의응답과 같은 광범위한 자연어 처리 작업을 높은 정확도로 할 수 있게 된 것이다. 그 덕에 Open AI의 GPT, 구글의 BERT, Meta의 OPT와 같이 인간의 언어 능력과 유사한 대규모 모델이 출시되기 시작했다.
이후, 언어 모델이 발달한 덕에 인터넷상의 데이터뿐만 아니라 이미지/영상/음성 등의 데이터를 적극적으로 사용할 수 있게 되었다. 트랜스포머 모델이 텍스트뿐만 아니라 이미지, 비디오 등의 다른 데이터를 학습하기 시작하면서 더 많은 영역에 응용될 수 있는 범용성을 갖추게 되었고, 이를 본 스탠퍼드대학교 연구진은 2021년 8월 발표한 논문에서 트랜스포머 모델에 ‘기초 모델(Foundation Model)’이라고 이름을 붙이며 인공지능 패러다임의 변화가 시작했다고 평가하기도 했다.
해당 스탠퍼드 대학교 논문
“On the Opportunities and Risks of Foundation Models”
Foundation Model
기초 모델은 대규모 데이터를 학습하여 만들어진 사전 학습 모델(Pre-trained model)이며, 이를 활용하여 다른 task를 수행하는 모델을 개발한다는 점에서 ‘기초’ 모델이라는 이름이 붙었다.
<그림3> 같이 도식화할 수 있는데 텍스트, 이미지, 발화 등 여러 가지 형태의 데이터를 사전 학습시켜 모델을 만들고, 기초 모델을 토대로 다양한 분야에 활용하는 구조이다. 1) 데이터를 학습하는 ‘사전 학습(Pre-training)’ 부분과 2) 기초 모델을 ‘적용(Adaptation)’하는 단계로 나눠서 볼 수 있다. 관련해서는 뒤에서 더 자세히 다뤄보겠다.
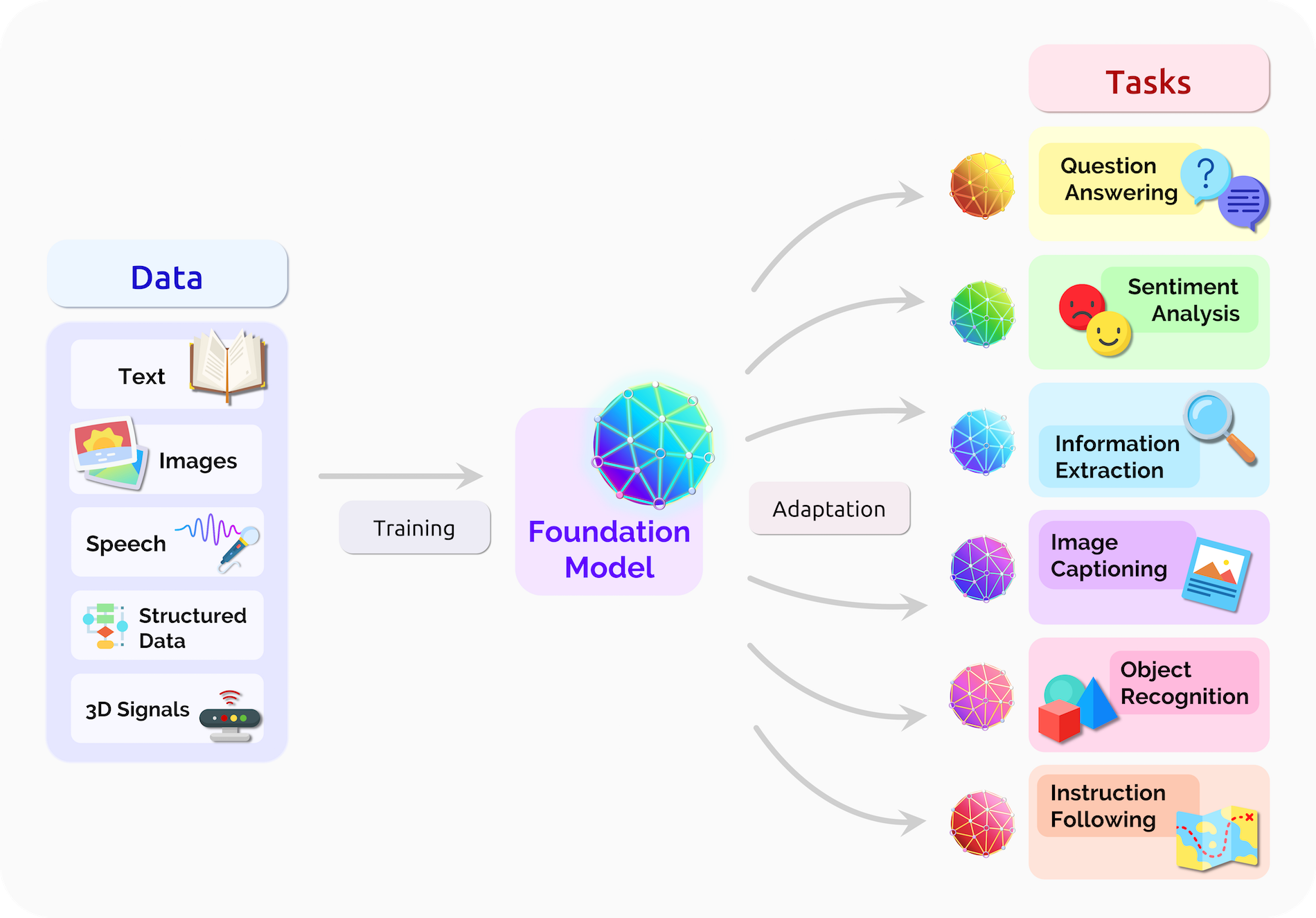
[요약]
Foundation Model = Pre-trained Model = Transformer Model
위의 단어는 의미상 유사하며, 그 예시로 BERT, GPT 등이 있다.
②기존 데이터 학습
생성 모델을 어떠한 데이터로 얼마만큼, 어떠한 방식으로 학습시킬 것인지는 굉장히 중요한 문제이다. 비단 인공지능 연구자뿐만 아니라, 비즈니스 분야에서 사업 기회나 투자 기회를 찾는 사람들 또한 각자 분야에서 도움이 될 것이다. 여기서는 기본적인 개념인 ‘매개 변수와 학습 데이터’, ‘학습 비용’, 그리고 ‘학습 방식’을 다룬다.
매개 변수와 학습 데이터
기초 모델의 학습에서는 ‘매개 변수(Parameter)’와 ‘학습 데이터(Training Data)’ 두 가지가 중요하다.
[매개 변수]
매개 변수는 입력값에서 정답을 만들어내는 조건을 의미한다. ‘3 x ? = 9’라는 문제가 있을 때, ‘3’을 ‘입력값’이라고 하고, ‘9’를 ‘출력값(= 레이블 = 정답)’이라고 한다. 입력값과 출력값을 활용하여 매개 변수값을 찾아내는 과정을 사전 학습이라고 하며, 이때 매개 변수의 값은 ‘? = 3’이 되고 가중치(Weight)라고도 부른다.
매개 변수의 수가 많다는 것은 문제를 많이 풀었다는 것과 같은 의미로, 그 수가 모델이 데이터를 얼마나 잘 학습하고 표현할 수 있는지에 영향을 끼친다. 한편, 매개 변수가 많을수록 더 복잡한 관계와 패턴을 학습할 수 있는 성능을 지니지만, 머신러닝을 위해 더 많은 학습 데이터가 필요하게 된다.
[학습 데이터]
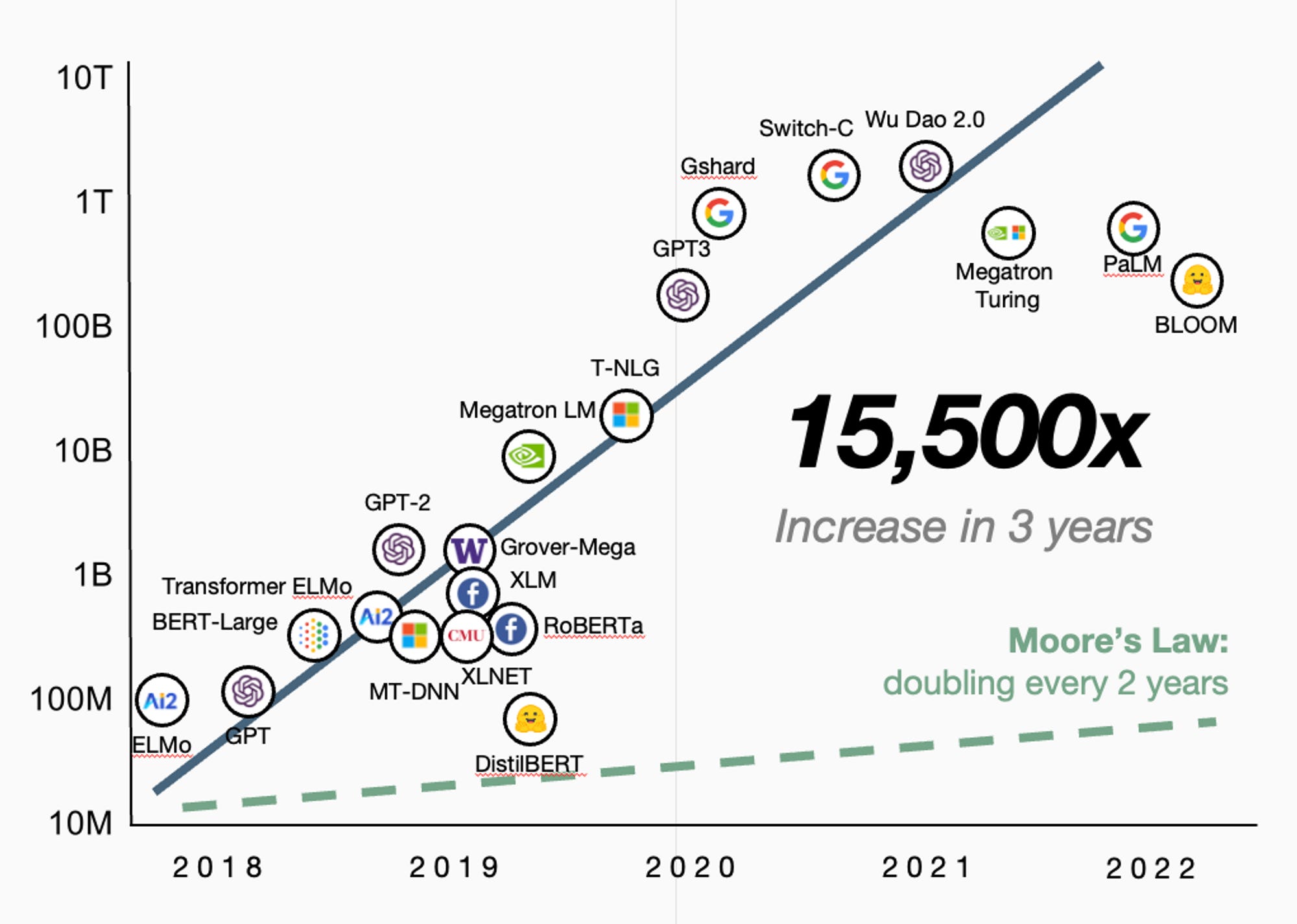
학습 데이터의 양, 품질, 다양성은 매개 변수와 마찬가지로 사전 훈련에서 매우 중요하다. 적은 양을 학습한 모델보다 대용량 고품질 데이터를 학습한 모델일수록 기계가 처음 보는 데이터(Unseen data)를 잘 예측하고 일반화할 수 있기 때문이다. 기초 모델의 개발 목적이 다양한 분야에 범용적으로 사용할 수 있는 모델을 개발하는 것이므로 최근에는 더 많은 학습 데이터를 학습시켜 대형 모델을 개발하는 추세이다.
학습 비용
매개 변수와 학습 데이터를 통제가 가능한 최대 수준까지 학습시키면 더 나은 모델을 만들 수 있겠지만, 문제는 비용이다. 학습 비용은 ‘준비물’과 ‘수업료’ 두 가지로 구성되어 있다고 빗대어 설명할 수 있다.
[준비물 = 데이터 비용]
‘준비물’은 매개 변수와 학습 데이터 자체를 확보하는 일을 의미한다. 먼저 매개 변수를 높이는 방법으로는 모델의 레이어 수를 늘리거나 더 큰 사전 훈련 데이터 세트를 사용하는 방식 등이 있다. 전자는 뇌의 뉴런 수를 늘린다고 생각하면 되고, 후자는 모델에 선행학습을 더 시킨다고 이해하면 편하다.
한편, 학습 데이터는 ImageNet, Pascal VOC, MScoco 등과 같이 공개된 대규모 데이터 세트를 활용하거나 웹사이트, 기사, 온라인 서적/논문 등 인터넷상의 수많은 자료를 전처리하여 확보할 수 있다. 이러한 과정을 통해 매개 변수와 학습 데이터 자체를 확보하는 단계에서는 데이터 확보, 저장, 관리 비용이 발생한다. 최근 모델처럼 막대한 양의 데이터를 요구하는 경우 비용이 그만큼 커지는 것이다.
[수업료 = 사전 학습 비용]
학습을 위한 준비물을 마련했다면, 모델을 학습시키는 일이 남았다. 매개 변수와 학습 데이터 정보가 공개된 OpenAI의 GPT 시리즈를 사례로 알아보자.
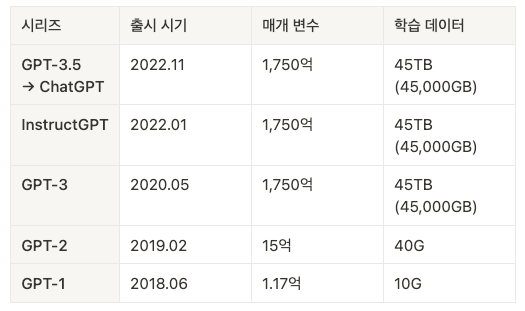
GPT는 시리즈마다 약간의 차이가 있지만 기본적으로 트랜스포머 모델로 그 규모가 매우 크다. 특히, GPT-3, GPT-3의 개선된 버전인 InstrcutGPT, ChatGPT에 사용된 GPT-3.5는 매개 변수가 1,750억 개, 학습 데이터가 45테라바이트로 알려져 있다. 이는 5년 전 처음 공개된 GPT 시리즈에 비해 그 규모가 각각 1,500배/4,500배만큼 커진 것이다.
딥러닝 인프라 회사인 Lambda Labs의 계산에 따르면, GPT-3의 1,750억 개의 매개 변수 신경망을 훈련하기 위한 한 번의 사이클을 도는데 최소 460만 달러(약 53억 원)가 사용되었을 거라고 추산한다. 이 계산은 오로지 컴퓨팅 비용만을 추산한 것으로 인건비, 매개 변수와 학습 데이터 확보/전처리 비용, 슈퍼컴퓨터 같은 장비 등 다른 비용은 포함되지 않았다.
이처럼 현재는 학습 비용이 일종의 진입장벽일 수 있으나, 점점 감소하는 컴퓨팅 한계 비용과 급격히 성장하는 분야에서는 후발주자의 개발 속도도 만만치 않게 빠르다는 점을 고려한다면 기초 모델 개발의 일인자가 정해졌다고 보기는 어려우며 언제든 새로운 강자가 등장할 수 있을 것이다.
학습 방식
기초 모델은 자기 지도 학습(SSL, Self-supervised learning) 방식으로 대량의 데이터를 학습한다. 자기 지도 학습이란 주석 정보가 없는 데이터(Unannotated data)에서 데이터의 특징을 뽑아내는 방식이다. 다시 말해, 데이터에서 필요한 부분을 ‘스스로’ 뽑아서 ‘지도 학습(정답을 찾아가며 학습)’을 한다.
자기 지도 학습은 데이터 가공 과정이 거의 필요하지 않다는 점에서 규모를 키우기에 유리할 뿐만 아니라 기존 방식으로 개발된 모델보다 SSL을 한 모델의 사용성이 훨씬 높고, 경제적으로 유리하다. 실제로 이 학습 방식은 BERT, GPT 시리즈, RoBERTa, T5 등의 최근 개발된 모델에서 적용됐다.

그렇다면, 어떤 원리로 라벨(정답) 없이도 학습이 진행되는 걸까? 자기 지도 학습법은 하나의 데이터 샘플에서 일부분을 활용해 다른 부분을 예상하는 방식인 ‘Self-Prediction’ 방식과 여러 샘플 간의 관계를 예상하는 방식인 ‘Contrastive Learning’ 방식으로 구분된다. 이 중 가장 대표적인 방식을 예시와 함께 알아보자.
[자기 지도 학습법의 구분과 종류]
참고 자료 : OpenAI PPT 슬라이드
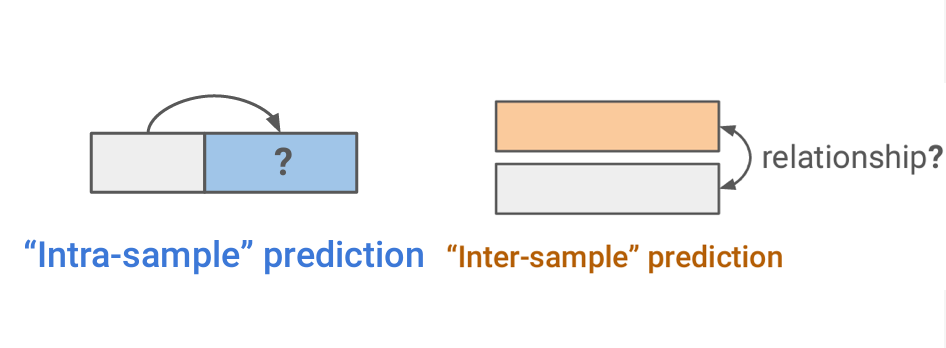

대표적으로 Self-Prediction 방식의 ‘Masked generation’은 데이터의 일부를 가리고 나머지 부분을 통해 가려진 부분을 예측하는 방식이다. 간단하게 ‘빈칸 채우기’라고 이해해도 좋다.
예를 들어, ‘지각해서 선생님께 ___을 들었다’는 문장이 있을 때, 앞뒤 문맥을 파악하여 빈칸에 ‘꾸중’이라는 단어를 집어넣는 식이다. 2018년 구글이 공개한 BERT가 바로 이 방식을 활용하여 사전 학습한 모델이며, 문장뿐 아니라 이미지 영역에서도 이러한 방식이 활발히 사용된다.
지금까지 생성형 인공지능의 개념 중 ‘모델’과 ‘학습’까지 설명했고 이를 사용할 단계만 남았다. 수많은 데이터를 학습한 대형 모델이 어떻게 다양한 분야에 활용될 수 있는지 알아보자.
[요약]
생성형 인공지능 모델의 학습 데이터 크기와 모델의 성능은 양의 상관관계를 지니며,
최근 자기 지도 학습 방식을 통해 대량 데이터를 효과적으로 학습할 수 있게 되었다.
③ 새로운 결과물 생성
기초 모델의 개발 생태계는 (1)데이터 생성 → (2)데이터 선별 → (3)사전 학습 → (4)적응 → (5)사용 영역으로 구성된다.
(1)인간의 활동을 통해 생성된 데이터를 (2)데이터셋으로 선별하고 (3)이를 학습시켜 기초 모델을 만든 뒤, (4)기초 모델을 활용하여 특정 작업을 위한 새로운 모델에 적용하고 (5)실제로 사용하는 것이다.
앞서 생성형 인공지능의 정의 ①과 ②에서 기초 모델의 개념을 시작으로 학습 단계까지 알아봤으니 ‘적응’과 ‘활용’ 영역을 살펴보자.
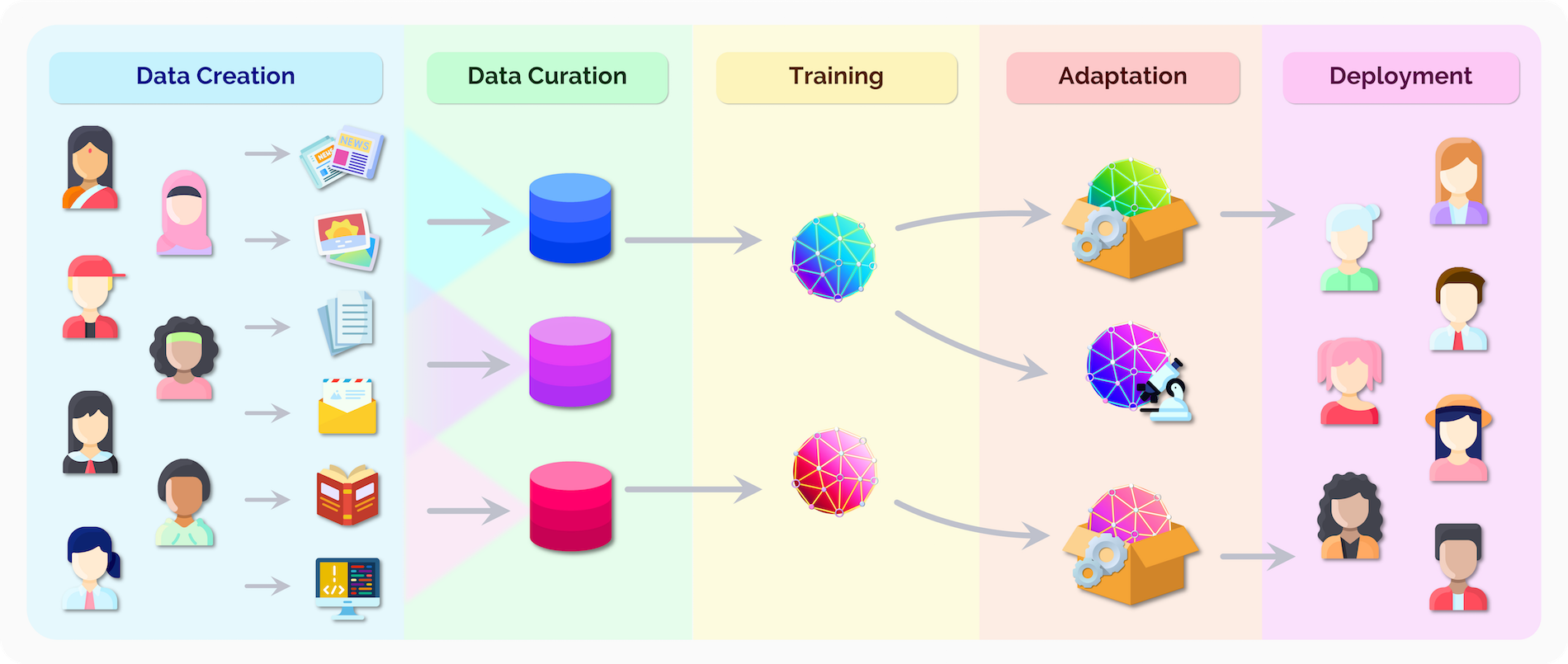
적응(Adaptation)
기초 모델이 대량 데이터를 사전 학습하여 여러 작업에 사용할 수 있는 표현(Representation)을 갖춘 것은 사실이지만, 특정 작업이나 도메인에 최적화되어 있는 것은 아니다. 따라서 일반적인 데이터를 학습한 기초 모델을 구체적인 상황이나 분야에 사용하기 위해서는 적응 단계가 필요하다. 주로 다음의 5가지 목적을 위해 ‘적응’ 단계를 진행한다.
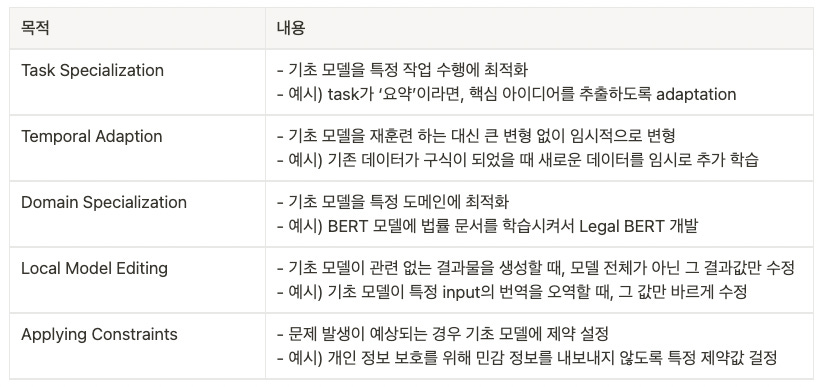
어떤 목적이든 기초 모델을 제대로 사용하려면 사전 학습 모델 활용하여 다른 분야에 적용하는 ‘전이 학습(Transfer Learning)’을 거쳐야 한다. 전이 학습은 데이터가 너무 적어서 처음부터 전체 모델을 학습할 수 없을 때 많이 사용되며, 이를 수행하지 않은 모델보다 빠르고 높은 정확도를 달성할 수 있다.
실제로 Facebook AI Research에 따르면, 사전 학습을 통해 데이터의 보편적인 특징과 패턴을 이미 학습했기 때문에 모델을 처음부터 훈련하는 것(train from the scratch)보다 전이 학습 방식이 2~3배 시간이 단축된다고 한다. 굳이 비유하자면 고1 함수 문제를 풀게 하기 위해 어린이에게 관련 정보를 학습시키는 것보다 중2짜리 학생에게 약간의 지식을 더 알려주는 것이 더 빠르고 정확한 것과 비슷한 논리이다.
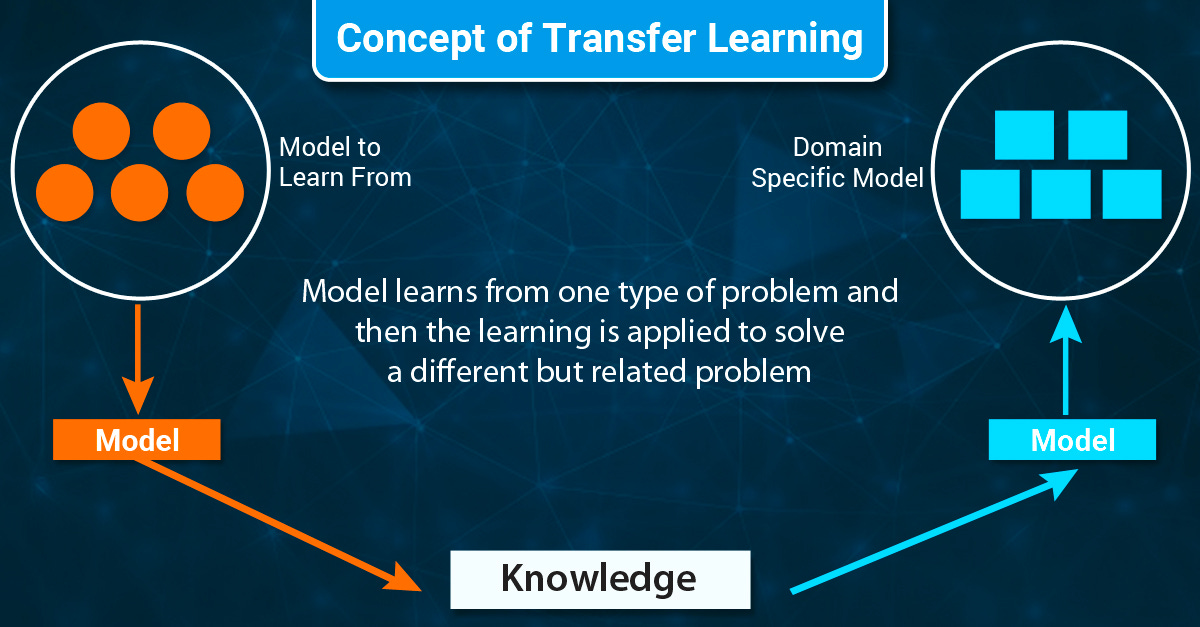
범용성이 높은(Task-agnostic) 기초 모델을 전이 학습하는 구체적인 방법으로는 ‘Fine tuning’이 있다. 참고로, 기술 관점에서 약간 차이가 있지만 Transfer Learning과 Fine Tuning이라는 용어를 구분하지 않고 혼용하기도 한다.
[Fine Tuning]
파인 튜닝은 사전 학습 모델을 기반으로 아키텍처를 새로운 목적에 맞게 변형하고 이미 학습된 모델의 가중치를 미세하게 조정하여 학습시키는 방법을 말한다. 쉽게 말해, 대용량 데이터를 사전 학습한 모델에 그 보다 훨씬 적은 데이터로 특정 분야를 학습시키는 것이다. 해당 데이터의 크기와 유사성을 기준으로 Fine Tuning을 다양한 방식으로 적용하기도 한다.
문제는 최근 모델의 크기가 빠른 속도로 커지고 있어서 파인 튜닝을 적용하여 모델 전체를 업데이트하면 비용이 너무 많이 발생한다는 점이다. 그래서 비교적 비용과 가성비 측면에서 효율적인 In-context Learning을 함께 사용하거나 Prompt Tuning이 대안으로 제안된다.
[In-context Learning]
컨텍스트에 주어진 설명이나 예시를 통해 어떤 task를 수행해야 할지 추론하는 방식이며, 예시의 개수에 따라 Zero shot/One shot/Few shot learning으로 구분된다. 가령, Few shot learning의 경우 <그림8>처럼 ‘영어를 한국어로 번역’하라는 명령과 함께 여러 예시를 넣어주면 모델(가운데)이 task를 추론하여 수행하는 것이다.

예시를 통해 정확도를 높이는 방식이 유용하긴 하지만, 매번 명령문(Prompt)를 쓸 때마다 몇 개의 예시를 넣는 것은 번거로운 일이다. 따라서, 최근 모델은 Zero-shot일 때도 사용자의 요청을 정확하게 수행하는 방향으로 개발된다. 가장 최근 출시된 GPT-3.5에서는 리워드와 강화 학습 방식으로 훈련하여 사용자가 예시를 입력하지 않더라도 명령과 맥락에 맞는 최적의 답변을 생성한다.

[Prompt Learning]
Prompt-based learning은 in-context learning을 기반으로 모델이 적절하게 task를 수행할 수 있는 형태로 문제를 바꾸는 방법이다. 사전 학습 모델이 수행할 수 있는 형태로 문제를 재정의하는 방법(Pattern-Exploiting Training)과 다양한 형태의 prompt를 사용하여 출력된 결과를 앙상블 하여 성능을 높이는 방법도 있다.
사실 기초 모델을 활용해서 특정 영역에 특화된 모델을 만드는 기술적인 방법을 제대로 이해하려면 이보다 훨씬 깊은 수학적 지식과 컴퓨터 과학 지식이 필요하므로 앞서 설명한 몇 가지 대표적인 방식의 컨셉을 이해하는 것만으로 충분하다. 이제 생성형 인공지능을 어디에 사용하고 있는지 간단히 알아보도록 하자.
사용(Deployment)
마지막 단계는 Adapted AI Model을 실생활에 활용하는 단계이다. 정말 다양한 분야에서 상상할 수 있는 모든 사용 사례가 나오고 있다고 해도 과언이 아니다.

Jasper, Copy.ai 같은 대표적인 사례 외에도 수많은 회사와 프로젝트들이 있다. 특히 Writing, Coding, Speech, 3D, Image, Video, Music, Search 등의 분야에 많은 Application이 등장하고 있다. 더 구체적인 사례가 궁금한 분은 다음의 링크를 참고하면 된다.
Base10 VC의 정리
AI / ML Company Database - Altimeter
Future Tools - 작지만 다양한 시도 모음
이 중 많은 회사와 프로덕트가 사라지겠지만, 강력한 가치 제안(Value Proposition)을 통해 사용자를 얻고(Acquisition) 유지함(Retention)과 동시에, 사용자들의 활동에서 생성되는 데이터를 수집하여 데이터 해자(Data Moat)를 구축한 기업이 살아남을 수 있을 것이다. 또한, 이러한 과정은 일회성 과정이 아닌 순환형의 flywheel이 되어야 장기적으로 유지 가능한 비즈니스가 되지 않을까 싶다.
[요약]
기초 모델은 범용성을 지니지만 그 자체로 사용하기 어려우므로,
목적에 맞는 모델로 발전시키고 이를 실생활과 비즈니스에 활용한다.
마무리
이번 글에서는 생성형 인공지능의 기본과 저변 개념을 다뤄보았다. 여기까지 성실하게 읽은 독자라면, 초반에 제시한 생성형 인공지능의 정의가 - ‘①생성 모델을 기반으로 ②기존 데이터를 학습하여 ③새로운 결과물을 생성하는 인공지능’ - 이제는 조금 더 깊게 이해될 것이라 믿는다. 다음 글에서는 현재까지 등장한 의미 있는 사례를 살펴보며, 생성형 인공지능의 가능성, 비즈니스 구조와 기회에 관해 다뤄보도록 하겠다.